Here is what I learned during a hackathon on Ethereum on Saturday. We started with theory and ended with an example. Personally I find it easier to go from the specific to the general, and found that things came together more once we got concrete, so thats what I’ll do here.
Starting with a very concrete thing, Ethereum has a browser that is a forked version of WebKit, with the Ethereum Javascript API embedded. It’s called AlethZero.
 .
.
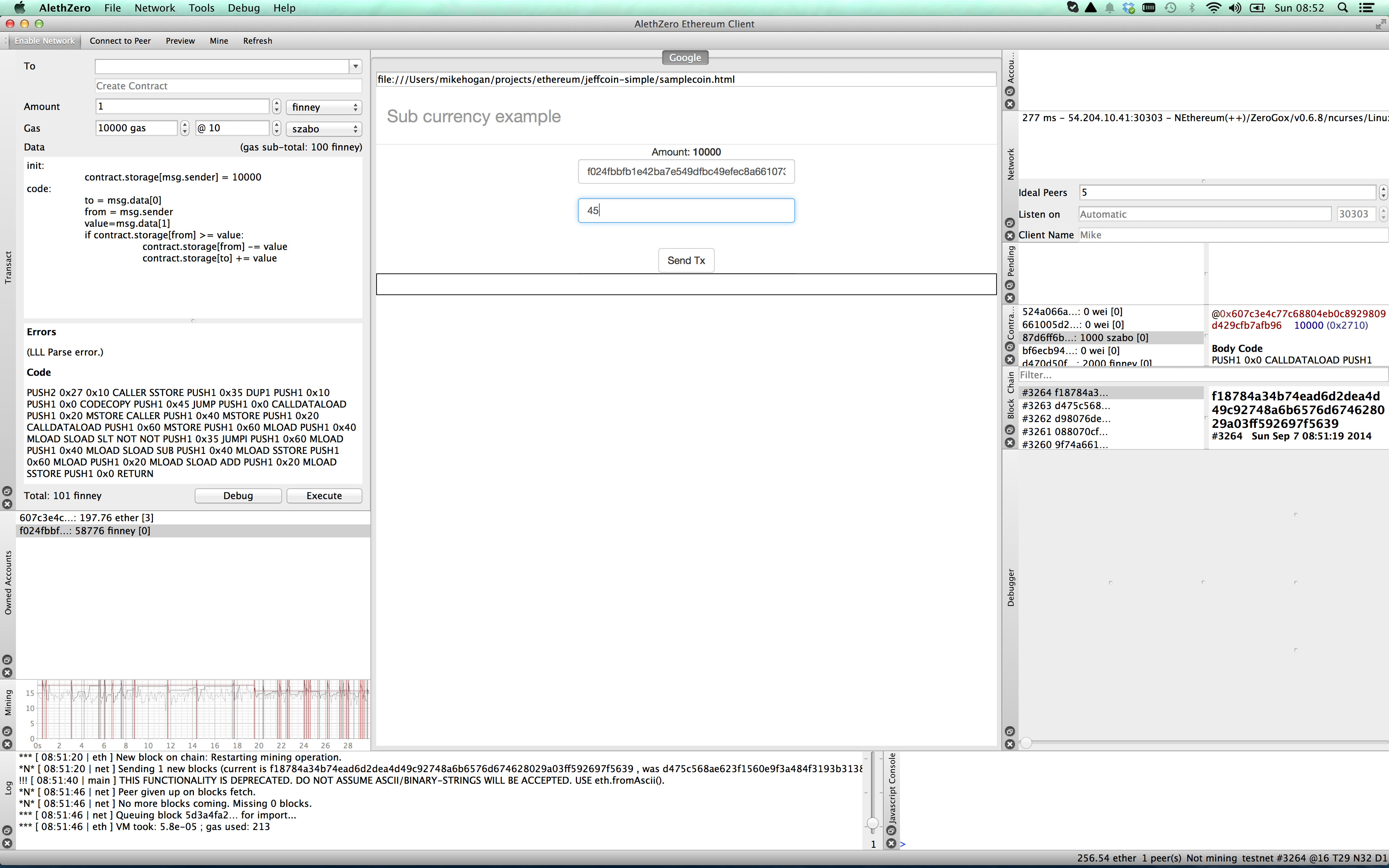
The panel in the middle is the browser, showing the Google home page, and all around it are panels showing information about the Ethereum network, and an area to define and execute contracts.
So lets say we want to make our own coin, MikeCoin. Making your own coin seems to be the Hello World of Ethereum.
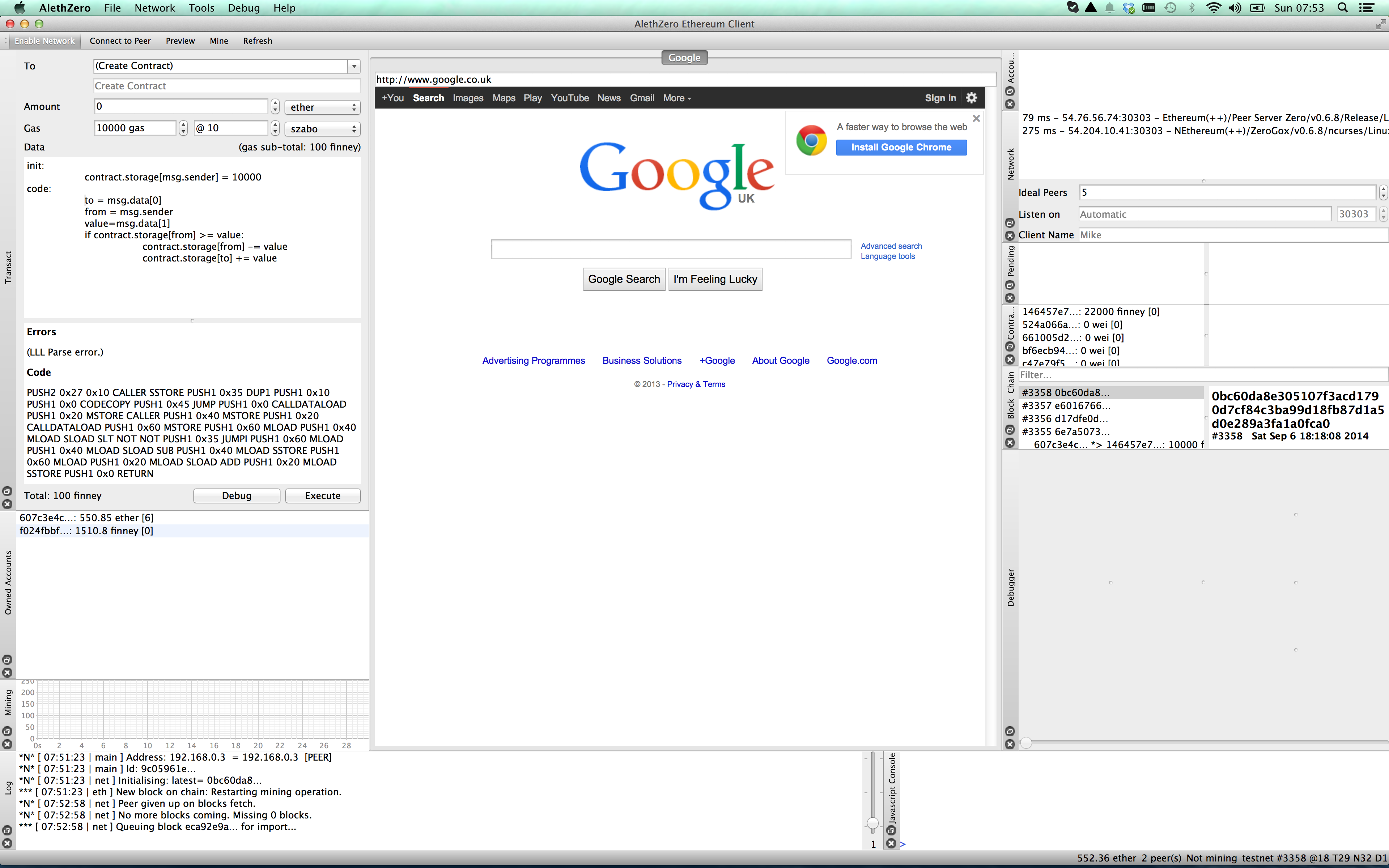
Write up the contract as shown below.
init:
contract.storage[msg.sender] = 10000
code:
to = msg.data[0]
from = msg.sender
value=msg.data[1]
if contract.storage[from] >= value:
contract.storage[from] -= value
contract.storage[to] += value
The code you write is in the middle left, starting with init:. Underneath this you see your code compiled into opcodes for the Ethereum virtual machine. If there is a problem with your code, you will see error messages in this panel.
What this contract does is define some storage, a slot in a distributed key-value store, with an initial value of 10000, and the key being the address of the person who sent the message. Who is the person? It will be me, because as soon as I press the Execute button, I will be sending this contract to the blockchain, so I am the sender of the message.
The init: block gets run once when the contract is getting setup on the blockchain. In effect we are defining a wallet with initial funds, all of which are owned by me.
The code: section of the contract is what you subsequently transact with. Essentially its stating that “this contract takes two parameters, the first is who we want to send coin to, the second is how much”. The if statement is saying “If the from wallet has enough in it, transfer the nominated value to the nominated wallet”.
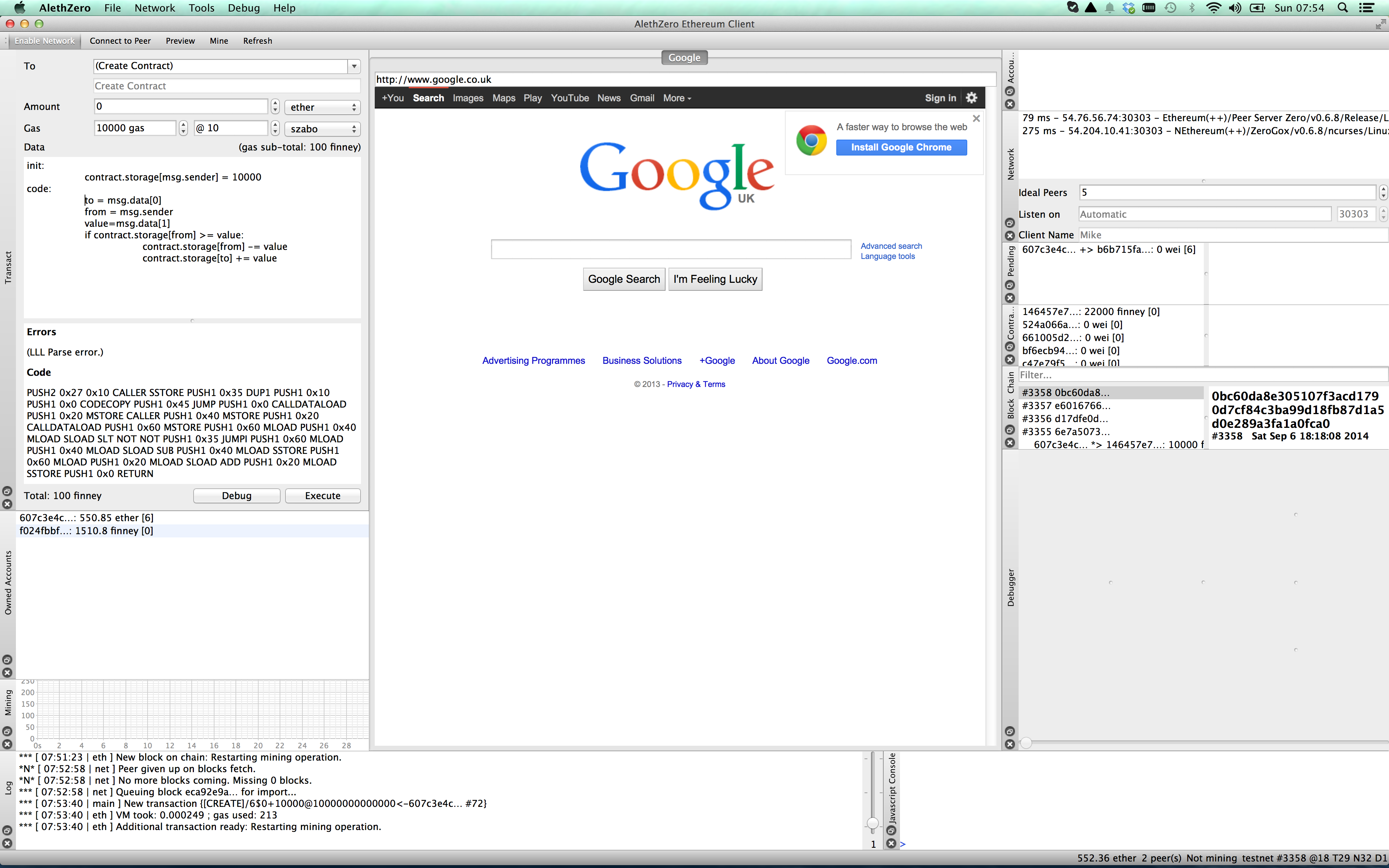
So we have coded up a very simple contract that stores funds and allows transfers. When we press Execute, this contract is sent to the blockchain. You will see it in the Pending tab, middle right.
What this is saying is that my account, starting “607c3” is sending the contract code to the network, and when mining finishes, my contract will have the address starting with “3726”. When I enable mining (menu item, top left), I see the Pending message disappear, and my contract appear in the contracts tab. I can double click this contract to copy its address to the clipboard. So I can see its full address is 37261aa159eb8999164e487a3d29883adc055d9d .
So now lets write a web page to allow people send MikeCoin. I can use my existing website development skills to layout the UI, the many users of MikeCoin will interact with it using AlethZero (a forked browser, remember). So I can layout a simple form using boostrap:
<div class="container">
<div class="header">
<h3 class="text-muted">Sub currency example</h3>
</div>
<div class="jumbotron ">
<div>Amount: <strong id="current-amount"></strong></div>
<div id="transactions">
<div class="form-group">
<input id="addr" class="form-control" type="text" placeholder="Receiver address"/><br>
<input id="amount" class="form-control" type="text" placeholder="Amount"/><br>
</div>
<button class="btn btn-default" onclick="createTransaction();">Send Tx</button>
</div>
</div>
</div>
And now I can crank out my javascript skills to show my balance in this wallet:
var contractAddress = "37261aa159eb8999164e487a3d29883adc055d9d"
eth.watch({altered: {at: eth.key, id:contractAddress}}).changed(function() {
document.getElementById("balance").innerText = eth.toDecimal(eth.stateAt("0x" + contractAddress,eth.secretToAddress(eth.key)))
});
This is saying “watch for changes in the contract, and when they happen, get my state in that contract and display it”.
What about sending funds to somebody else? Here is the createTransaction() code:
function createTransaction() {
var addr = ("0x" + document.querySelector("#addr").value).pad(32);
var amount = document.querySelector("#amount").value.pad(32);
var data = (addr + amount).unbin();
eth.transact({
from:eth.key,
to:"0x" + contractAddress,
data:data,
gas:10000,
gasPrice:10
},function(receipt){
alert(receipt);
});
}
You can find docs on the transact function on the wiki, but basically this is saying “send a message from me to the contract, with the data of the message being two items: the destination address and an amount, in keeping with the params the contract expects.”
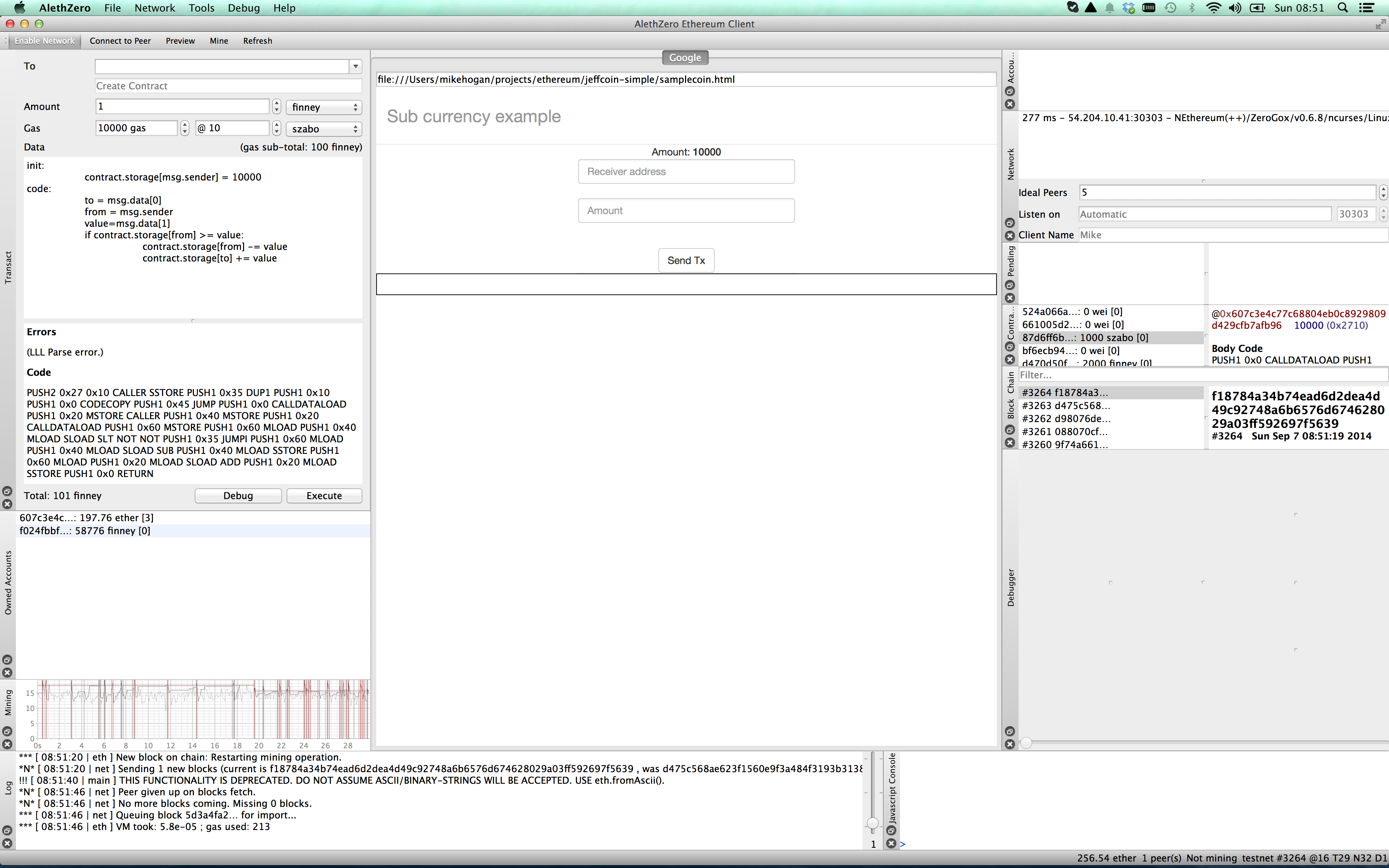
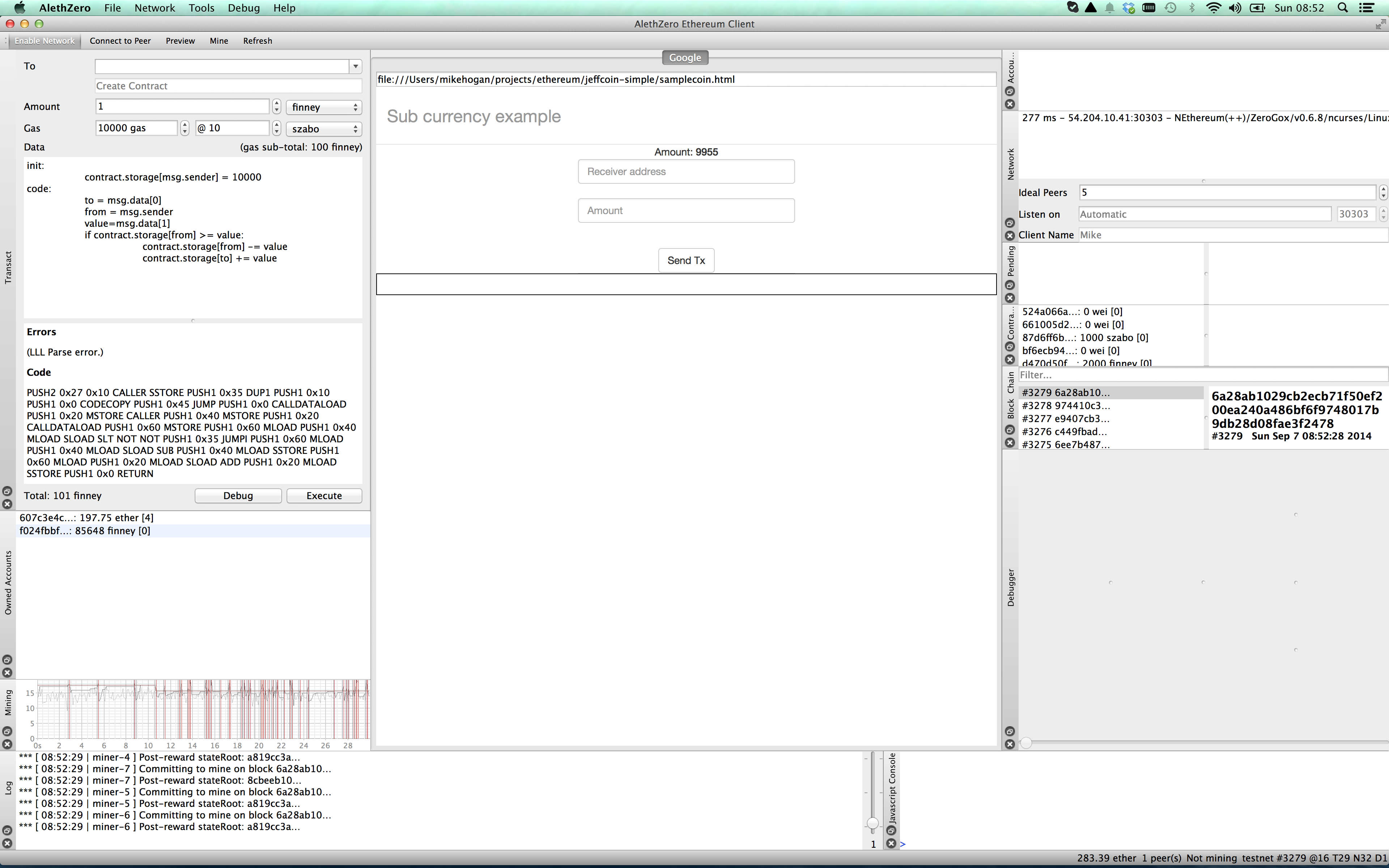
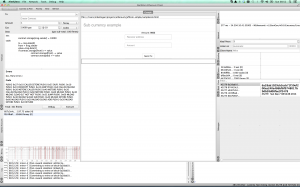
This is how the page looks in AlethZero.
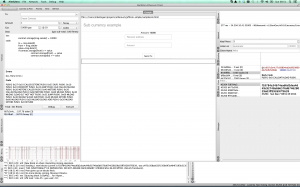
Lets say I want to send some coin to somebody else. You will notice in the screenshots that in the bottom left quarter there is an Owned Accounts panel, and I have in there a second account I created, beginning with f024. Rather than bother other people with MikeCoin, I will send coin from my main account beginning 607c to this second one.
So I put in the destination account and an amount, and press Send Tx.
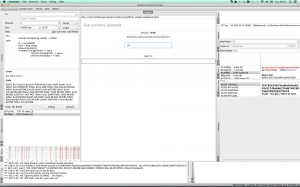
I will see the transaction appear in the Pending panel, then, assuming mining is running, it will disappear. Unfortunately my watch code is not live-updating and I am not sure why, but if I refresh the page I can see the money has left my wallet.
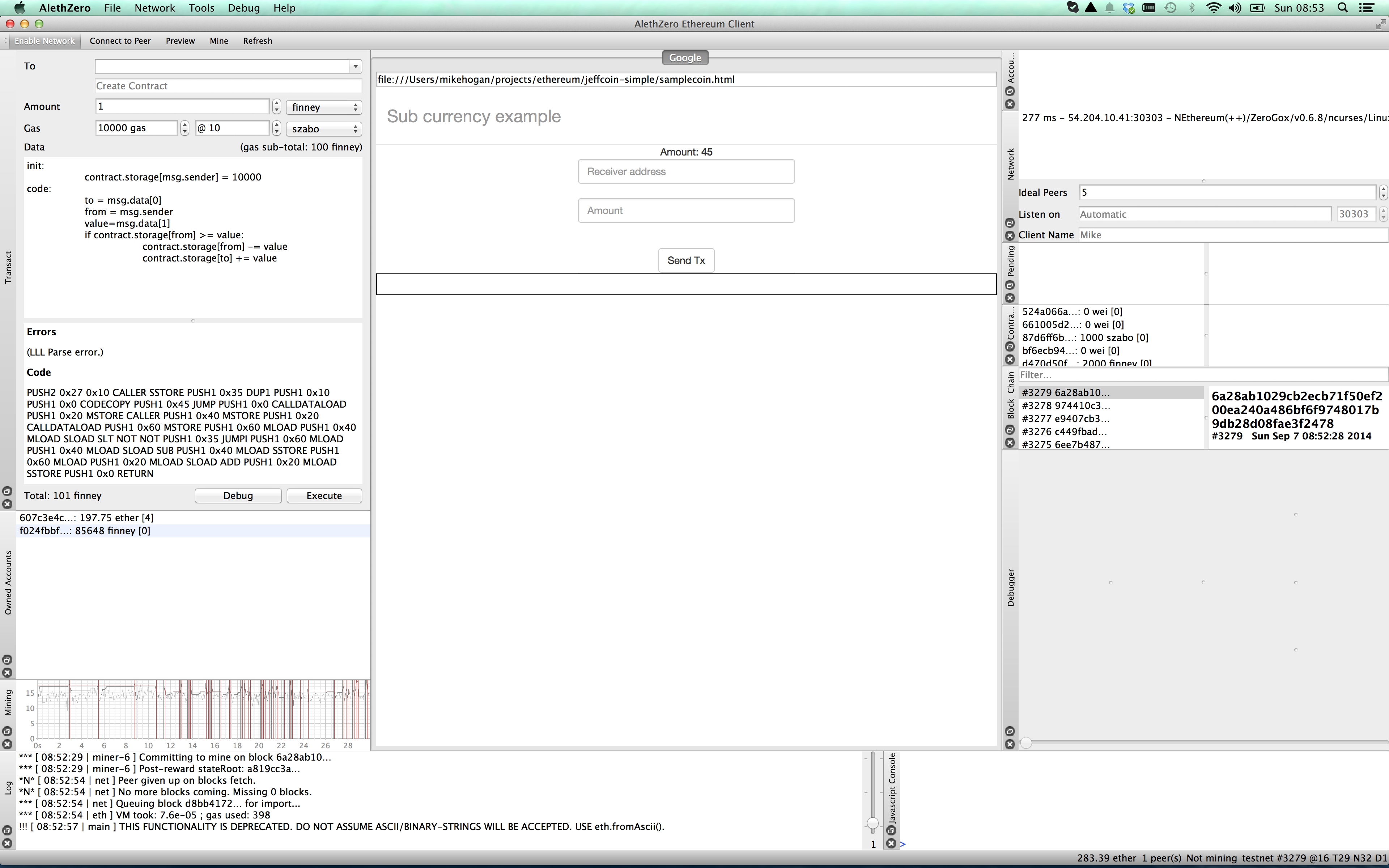
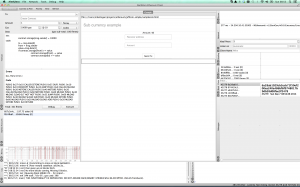
How can I check that my second account has the money? Well I will cheat a bit and change the code of the app to show the balance of my second account:
eth.watch({altered: {at: eth.key, id:contractAddress}}).changed(function() {
document.getElementById("balance").innerText = eth.toDecimal(eth.stateAt("0x" + contractAddress,eth.secretToAddress(eth.keys[1])))
});
And when I refresh the page, I see that I own 45 MikeCoin in my second account.
And that is about the most basic Ethereum contract and app, and its a very concrete, understandable thing. But what is it we are really dealing with here?
My contract exists as an addressable entity in a distributed blockchain that nobody owns or can shutdown, and it enforces rules about ownership of data that is also distributed. I have a browser that knows how to interact with these contracts and data. The Ethereum team are working towards putting the apps themselves in the blockchain, so they too will be distributed and decentralised – no url to a server that somebody owns.
I went to this hackathon expecting to learn about a “better bitcoin”, but pretty soon I started to think that this is in fact a re-envisioning of the internet, where centralised servers are replaced by a network of peers, urls are replaced by addresses on the blockchain, http is replaced by a low-latency torrent protocol (its called Swarm), and wesbites are replaced by distributed apps. No individual owns this kind of network, nobody controls it. That seems to me to be the vision.
My feeling towards the end of the day was that its less about learning the APIs of Ethereum, and more about getting with what can be built using this kind of tech. For me this requires unlearning some of what I know, and seeing what it is that I am assuming. If the internet can or will be rebuilt in a more decentralised, more ownerless way, what kinds of apps and business and economies will grow out of this?
The social media built on this kind of platform will not be Facebook or Twitter. In functional terms it might, but you will not be going to Facebook owned servers and they will not own your data. Also, there will be less need for a centralised search engine company, that implements the rules around what we get to see, and controls the information around what we search for.
Even if Ethereum does not end up re-defining the internet, the ideas contained in it show that its possible. My taken-for-granted world of http and urls and webservers is tenuous and I would be well served to not get too attached to them. Everything changes. So that was “bigger picture lesson one”.
But you know what the biggest bigger picture lesson for me was? The social element thats around this technology. I met one guy that no longer has a bank account and lives 100% on bitcoin. He paid for his coffee with @changetip. I met another that is 50% in bitcoin. Poeple are actually doing this, NOW.
The conversations that were happening around the table were like “Today, the people who get to write the contracts have the power. This way, we all get to write contracts”. It kinda felt to me like the Zeitgeist is shifting towards decentralisation, and Ethereum and tech like it is a lagging artefact bubbling up out of this mind shift. It was very stimulating and rewarding to immerse myself in this mind space. I’m going again on Oct 5th.
Write up by Chris Ellis on the day